
Research
Opinion Mining (Sentiment Analysis)
Attribute Extraction from the Web for Building Object-oriented Search Engine
IEEE/WIC/ACM Web Intelligence’15
ACM Symposium on Applied Computing (ACM SAC’16)
Researchers: Shintaro Nomura and Fumitaka Nakane
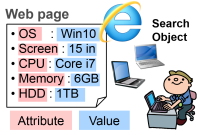 A large number of semi-structured documents (HTML documents) exist on the Web. To improve the accessibility of information related to an object, such as a product, human, or place, its attribute names and attribute values need to be extracted. In this work, we automatically extract attribute names from the Web pages by applying a bootstrapping algorithm. A bootstrapping algorithm is a new technique in natural language processing. It iterates creating a template for extracting values and extracting values using the templates. By introducing the key of the object (same notion of key in relational database) and also automatically extracting keys, we can obtain many attribute names. [PDF]
A large number of semi-structured documents (HTML documents) exist on the Web. To improve the accessibility of information related to an object, such as a product, human, or place, its attribute names and attribute values need to be extracted. In this work, we automatically extract attribute names from the Web pages by applying a bootstrapping algorithm. A bootstrapping algorithm is a new technique in natural language processing. It iterates creating a template for extracting values and extracting values using the templates. By introducing the key of the object (same notion of key in relational database) and also automatically extracting keys, we can obtain many attribute names. [PDF]
Hiding Spoilers from Online Review Comments
IEEE/WIC/ACM Web Intelligence’14
IEEE/WIC/ACM Web Intelligence’16
Researchers: Kyosuke Maeda, Hidenari Iwai and Kaori Ikeda
 Reviews of items including stories such as novels and movies sometimes contain spoilers (undesired and revealing plot descriptions). We propose a system that helps users see reviews without seeing such plot descriptions. This system classifies each sentence in a user review as plot-related or non-plot-related and hides plot descriptions from user reviews. We also proposed a method of generalizing people’s names, which we think is strongly related to the plot description. Finally, we implemented a display interface of user reviews in which users can control the level of plot hiding. [PDF]
Reviews of items including stories such as novels and movies sometimes contain spoilers (undesired and revealing plot descriptions). We propose a system that helps users see reviews without seeing such plot descriptions. This system classifies each sentence in a user review as plot-related or non-plot-related and hides plot descriptions from user reviews. We also proposed a method of generalizing people’s names, which we think is strongly related to the plot description. Finally, we implemented a display interface of user reviews in which users can control the level of plot hiding. [PDF]
Predictive Input Interface of Mathematical Formulas
Conference on Human-Computer Interaction (IFIP INTERACT’13)
Researchers: Keisuke Horie
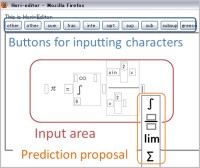 Currently, inputting mathematical formulas into a document using a PC requires more effort by users than inputting normal text. We propose a method for predicting user’s inputs of mathematical formulas using an N-gram model: a popular probabilistic language model in the natural language processing. Mathematical formulas are usually presented in hierarchical structure. Therefore, our method incorporates hierarchical information of mathematical formulas to create a prediction model. We try to realize high prediction accuracy of inputting characters for mathematical formulas. Note that although this study does not directly deal with opinion, but the used technologies is the same as opinion mining. [PDF]
Currently, inputting mathematical formulas into a document using a PC requires more effort by users than inputting normal text. We propose a method for predicting user’s inputs of mathematical formulas using an N-gram model: a popular probabilistic language model in the natural language processing. Mathematical formulas are usually presented in hierarchical structure. Therefore, our method incorporates hierarchical information of mathematical formulas to create a prediction model. We try to realize high prediction accuracy of inputting characters for mathematical formulas. Note that although this study does not directly deal with opinion, but the used technologies is the same as opinion mining. [PDF]
Estimating Reviewer Crediblity using Review Contents and Review Histories
IEICE Transactions of Information and Systems, Vol.E95-D, No.11, 2012
Researchers: Yuya Tanaka and Nobuko Nakamura
 Customer review comments are useful when people buy items in e-commerce sites. However, some reviewers provide less valuable information. This research identifies credible reviewers who provide valuable information in commercial Web sites. This study compare two major methods to measure credibility: 1) a method assessing reviewers based on the content of reviews and 2) a method assessing reviewers based on the review histories. Finally, we combine these two methods to improve the accuracy of assessment. [PDF]
Customer review comments are useful when people buy items in e-commerce sites. However, some reviewers provide less valuable information. This research identifies credible reviewers who provide valuable information in commercial Web sites. This study compare two major methods to measure credibility: 1) a method assessing reviewers based on the content of reviews and 2) a method assessing reviewers based on the review histories. Finally, we combine these two methods to improve the accuracy of assessment. [PDF]
HITS Algorithm using Anchor-related Text
IEICE Trans. of Information and Systems, Vol.E89-D, No.6, 2006.
Web Intelligence and Agent Systems, Vol. 8, No. 2, 2010.
Researchers: Bui Quang Hung and Masanori Otsubo
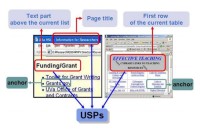 Kleinberg’s HITS algorithm is a popular algorithm to rank web pages. One of its problems is the topic drift problem. Previous researchers have tried to solve this problem using anchor-related text. We proposed another type of anchor-related text obtained analyzing the document structure of the page. We examine how much we can improve the HITS algorithm. We also compare several kinds of ancho-related text. The experimental results show that our method has improved the HITS algorithm in accuracy metrics. [PDF06] [PDF10]
Kleinberg’s HITS algorithm is a popular algorithm to rank web pages. One of its problems is the topic drift problem. Previous researchers have tried to solve this problem using anchor-related text. We proposed another type of anchor-related text obtained analyzing the document structure of the page. We examine how much we can improve the HITS algorithm. We also compare several kinds of ancho-related text. The experimental results show that our method has improved the HITS algorithm in accuracy metrics. [PDF06] [PDF10]
Social Summarization of Text Feedback for Online Auctions
ACM Conference on Intelligent User Interfaces (ACM IUI’06 Best Paper)
Researchers: Hanako Ohno and Yukitaka Kusumura
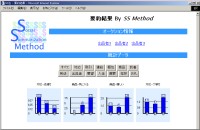 Buyers in online auctions write feedback comments to the sellers from whom the buyers have bought the items. This research detects expressions of courtesy from the review comments and presents the user as a summary excluding the courtesy expressions. For the detection, this research uses not only the target seller’s feedback comments but also feedback comments that one of the author of the above comments give to other sellers. By using the social relationship in the auction, it detects each author’s rare comment. Finally, we provide an interactive presentation method of the summaries. [PDF]
Buyers in online auctions write feedback comments to the sellers from whom the buyers have bought the items. This research detects expressions of courtesy from the review comments and presents the user as a summary excluding the courtesy expressions. For the detection, this research uses not only the target seller’s feedback comments but also feedback comments that one of the author of the above comments give to other sellers. By using the social relationship in the auction, it detects each author’s rare comment. Finally, we provide an interactive presentation method of the summaries. [PDF]
Text Mining Agent for Net Auction
ACM Symposium on Applied Computing (ACM SAC’04)
Researchers: Yukitaka Kusumura
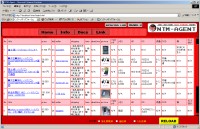 This research automatically generates a table which contains the features of several items in online auctions for comparison. We develop a system called NTM-Agent(Net auction Text Mining Agent). However, this brings a problem that item descriptions are written in free format and in informal manner. Also, item categorization is also done by seller’s own view point, and some of the items are not categorized correctly. For the second problem, NTM-Agent filters the items by correlation rules about the keywords in the titles and the item descriptions. For the second problem, NTM-Agent extracts the information by distinguishing the formats. [PDF]
This research automatically generates a table which contains the features of several items in online auctions for comparison. We develop a system called NTM-Agent(Net auction Text Mining Agent). However, this brings a problem that item descriptions are written in free format and in informal manner. Also, item categorization is also done by seller’s own view point, and some of the items are not categorized correctly. For the second problem, NTM-Agent filters the items by correlation rules about the keywords in the titles and the item descriptions. For the second problem, NTM-Agent extracts the information by distinguishing the formats. [PDF]